
Introducing Turbo Mode 🚀
April 11, 2025
Today’s update introduces our mode selector. It also introduces Turbo mode, a new and very fast retrieval option!
This is one of the ways we’ve simplified things for our users. AI models are confusing and unpredictable. We are working to maximise the value and minimise the complexity.
Don’t forget to subscribe!
Simple is better
Building products is a tension between a set of constraints:
- Desirable: people want to pay for it
- Feasible: current technology can solve it
- Viable: you can make money selling it
One of the key product challenges is balancing Desirable and Feasible.
Something I have always found frustrating is complex B2B products. I have experienced first-hand the apathy that business users have towards complex enterprise software products.
Complexity is never desirable.
Simplicity is always Desirable.
Anyone using LLMs is likely familiar with the overwhelming choice of ChatGPT, Claude, Gemini, Deepseek. Each comes with at least four variants. The product positioning of these is all very crude. Crude in the sense of crude oil: you are being offered a choice of crude oil when all you want is gas to drive to work.
So the question is, what does simple and refined look like in the world of LLMs?
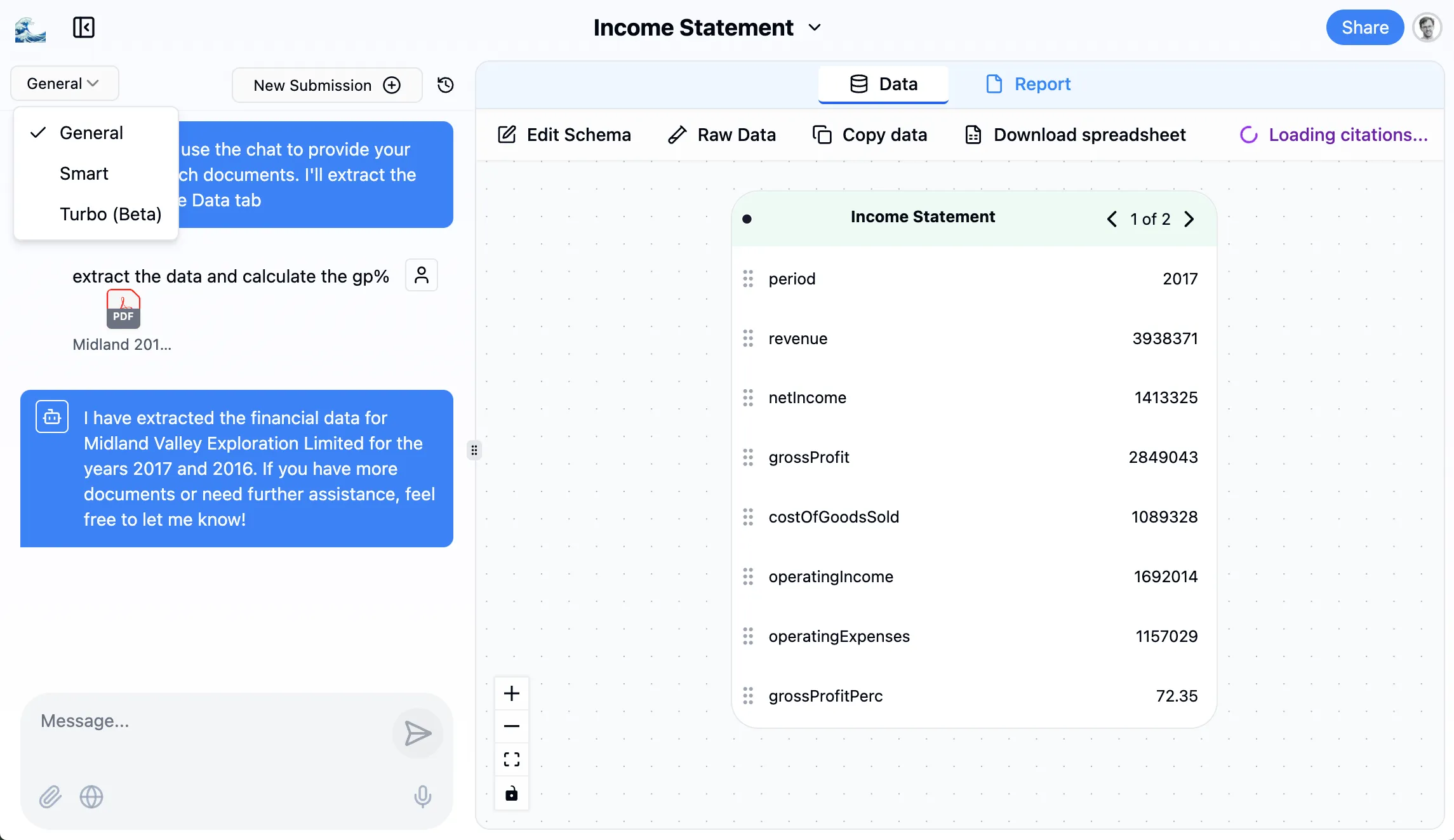
Mode selector
The agreement between Sea.dev and our customers: we figure out the messy details of using raw LLM intelligence to help get the job done.
We’ve released 3 modes to enable this:
- General: AI capabilities with good balance of speed and intelligence
- Smart: More intelligent, better for complex use cases with specific domain expertise
- Turbo: Designed for long repetitive tables (e.g., bank statements with many pages)
We’ve met our customers’ needs for varying capabilities, in a way that makes their decision easier.
Behind the scenes, we balance the tradeoffs for each use case!
(As an aside: Be extremely wary of any CRM or workflow provider that glosses over document processing as a solved problem)
Turbo mode
This solves an unmet need of flexibly ingesting long and repetitive documents.
General and Smart modes handle complex reasoning, but when a document is relatively simple and very long, you just want speed! 🚀
Turbo mode extracts, cleans, deduplicates, transforms, just like a data engineer!
Turbo is especially interesting, as it touches on my data engineering background, moving bulk data from source to target, and transforming it along the way.
The technical challenges were quite involved, but ultimately the user only has to specify the target, and Turbo creates a data pipeline on the fly to pipe the data into the target structure.
The tradeoff is explicitly in the favour of speed, but it is impressively accurate, and a serious breakthrough if you consider the alternatives to achieving the same outcome!
(Another aside: I personally feel like this is the future of data quality. There is a data engineering narrative around Shifting Left, and this is about as far left as you can shift in this context. Imagine an AI system building your semantic model, controlling the data schema used to capture data from customers, and having context of all downstream dependencies.)
Why this matters
All of this needs to be Viable! Who determines that? A customer’s willingness to pay!
Within our product, we are working to accelerate business lending.
One of the primary points of friction is getting information from potential borrowers.
In an ideal world, all the data would come straight from the accounting system into a cashflow algorithm to price the loan. This exists, but in reality often lacks key data and is at best only useful for simple loans.
Lenders need to better understand their customer’s business, and this means getting deep into the data.
Enabling our customers to easily win deals, with speed, accuracy, and conviction, is what we are here to do.
Fast, accurate document processing is one part of the puzzle.
Next steps
Have long complex documents, or bank statements that need processing? DM me or comment below, happy to show you what it can do!