
Matt Arderne
Co-founder @ Sea.dev
Welcome to the second post in a series explaining the Sea.dev app.
For more details on enabling Lending and Fintech teams to effortlessly extract data from businesses, people, and documents, please visit our website.
The Feature
Last time, we explored financial statements; this time, we introduce an innovative new feature:
Context-Aware Confidence Score
This is something that we’ve been quietly cooking in the background.
If you’ve ever used an Optical Character Recognition (OCR) tool, you know it typically assigns a confidence score to each extracted character or field, indicating how clearly the software recognized it. However:
What OCR confidence traditionally doesn’t consider is the context of the document.
Our context-aware approach goes a few steps further by assessing not only whether the text was recognized correctly but also whether it makes sense in the broader context, be it a financial statement, a chart, or any other structured document.

A Simple Example
A traditional OCR system might read color labels in a document and give each recognized word a perfect score if it’s spelled correctly:
🟢 Green
⚪ Grey
🔴 Red
An intelligent system would see the above and think:
“Hmm, usually 🟠 Orange goes between Green and Red? Let me check.”
We’ve built this “intuition” into our data extraction.
A context-aware confidence score tells you how much you can trust the extracted data. Instead of blindly accepting numbers, names, or terms from a document, you’ll know whether the system found an obvious match or if it’s making an educated guess.
The Impact
So what?
Indeed.
This is particularly helpful when pulling data from complex or inconsistent financial statements. If you work in Lending or Private Equity, you know how messy multi-entity consolidations and financial spreads can get—and how much of a time sink they can be if you have to manually verify every figure.
I know firsthand the pain of trying to automate group-level data consolidations using traditional OCR and spreading tools.
Let’s walk through a scenario involving two financial statements from the same company, published 15 years apart. The structure of the accounts changed in that time, so combining them can get tricky.
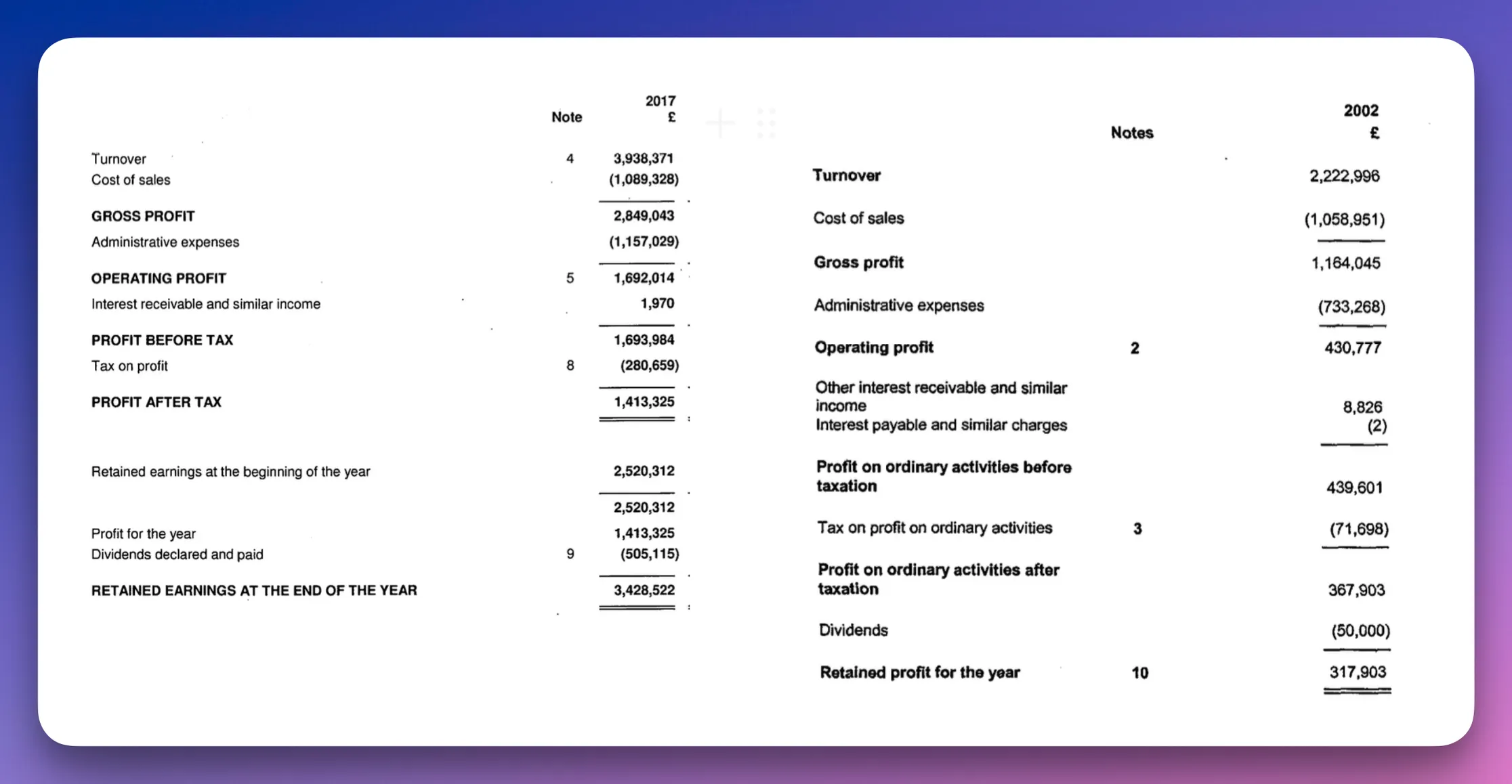
For simplicity, let’s just spread data from one company’s statements. In reality, we’ve seen huge efficiency gains in multi-entity spreads, consolidation, and EBITDA adjustments—often among the most time-consuming tasks in professional finance.
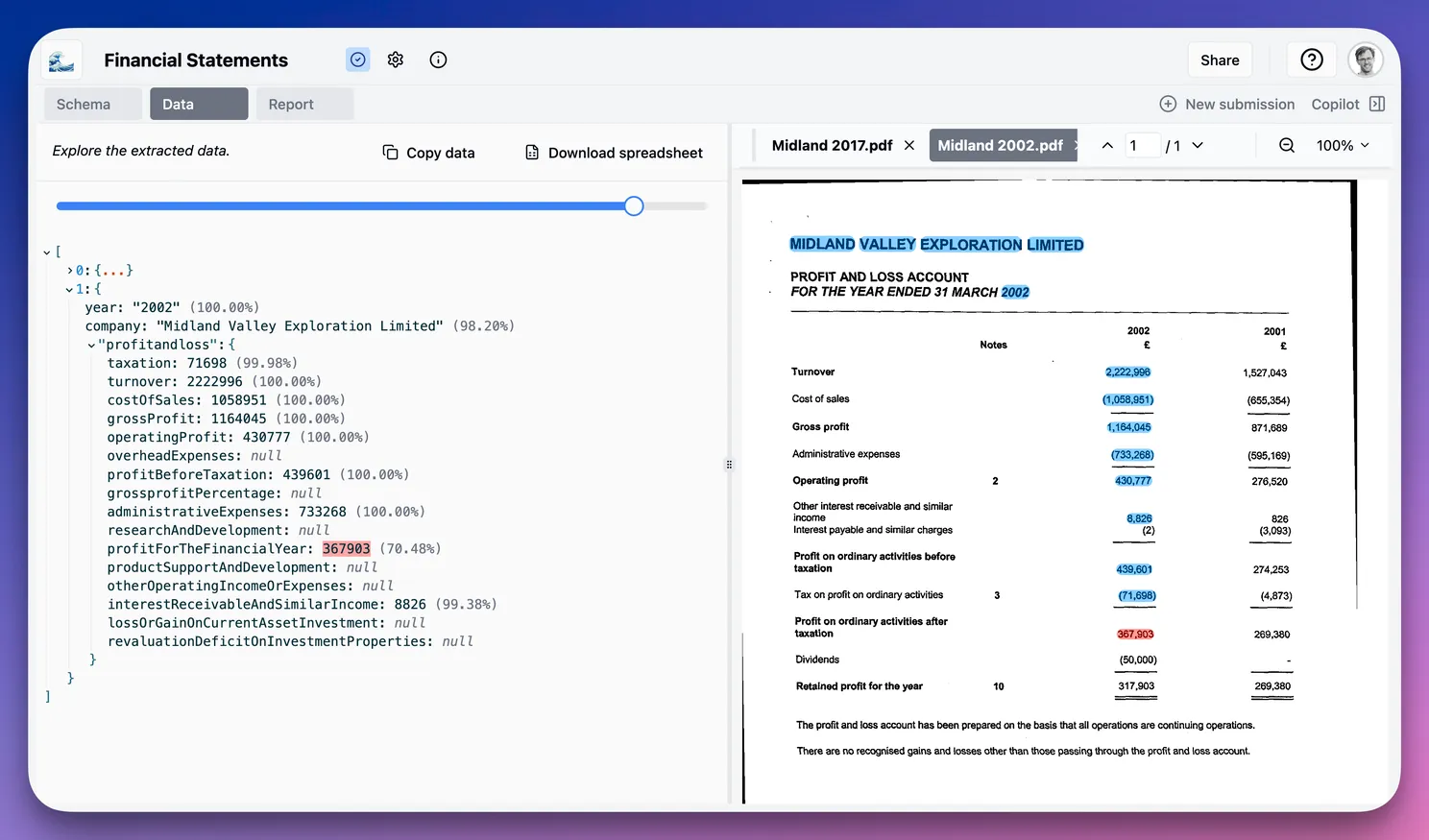
Spotting Potential Inconsistencies
When we extract both financial statements into the same target, we notice that certain line items, especially anything labeled profit, are flagged with lower confidence in the older statements. That’s because:
- Definitions of profit vary over time or across statements.
- We set our context-aware confidence threshold at 90%, so anything below that gets highlighted for review.
By contrast, the 2017 data shows very high confidence, primarily because the target structure was based on that statement.
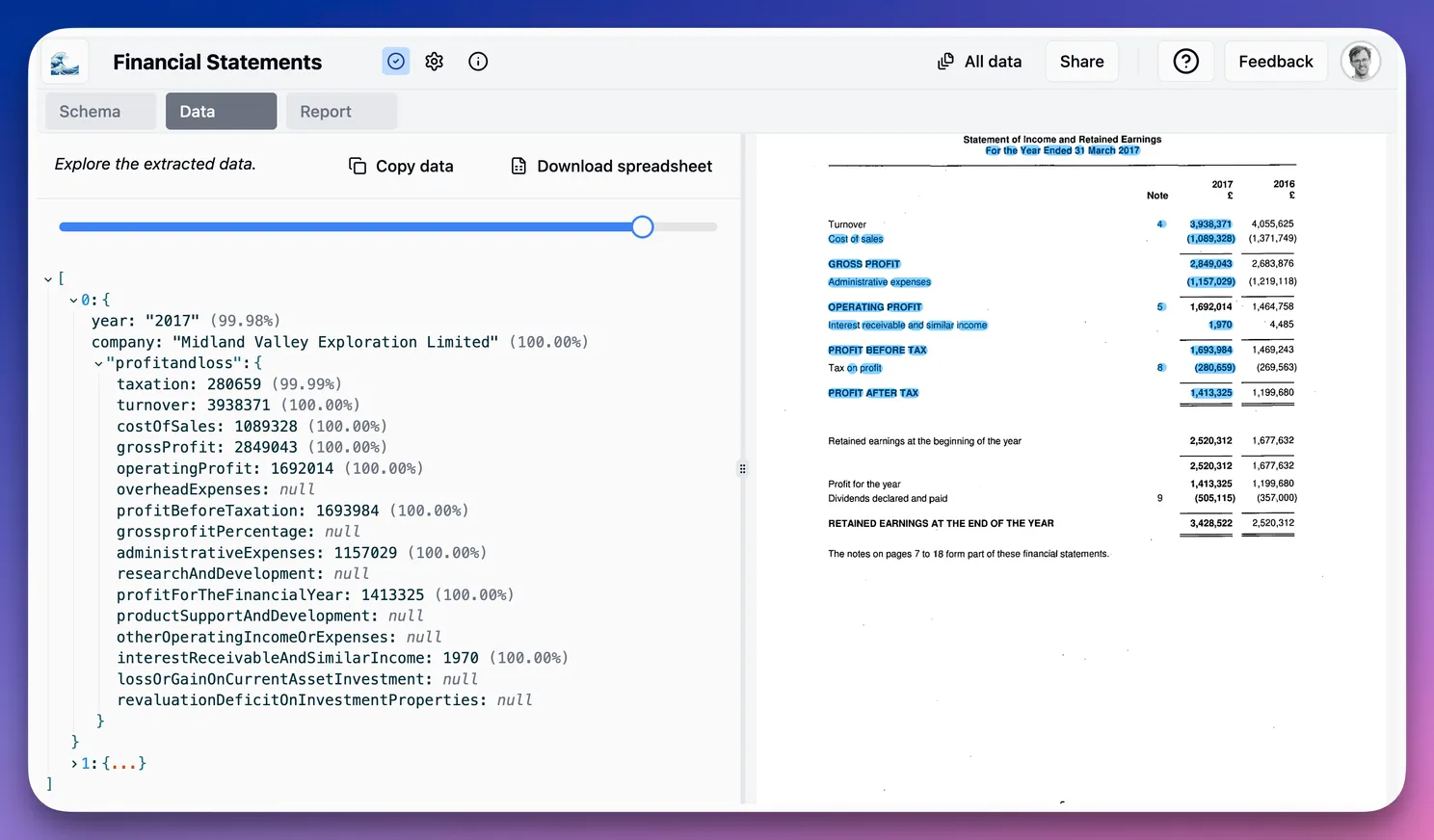
Great!
If some of the finance jargon lost you, here’s a meme to visualize why people do this process at all:
Start off with Revenue, and slowly “boil it down” 😅 until we are left with Income—which is what matters.

Exactly how you do this is highly context-dependent and is the cause for a lot of outsourcing, adjusting, and spreadsheet maneuvering!
Who says finance isn’t fun? 😆
Our ultimate goal? To automate the analysis of these performance metrics, whether you’re looking to lend, buy, or invest in a company.

Summary
Traditionally, software for these workflows is lacking in both flexibility and intelligence.
Worse, they are designed to be implemented by sales engineers rather than seamlessly adopted by finance experts.
At Sea.dev, our customers expect software that is easy, flexible, and powerful, with two major outcomes:
- 10x efficiency for credit analysts, similar to the automation boosts software engineers see with coding tools.
- The ability to reduce or significantly enhance outsourced credit teams by bringing more analytical power in-house.
Next Steps
If you’d like to test this out, comment below, and I’ll send you a link where you can recreate this workflow.
And if you liked the reference in the title, drop a 🧠 in the comments!